|
|
随着VOIP 的广泛应用以及多媒体通信技术的发展和成熟,人们对互联网语音通信的音频品质提出了更高的体验要求。主流的视频会议系统由原先的14 kHz升级到22 kHz 的音频带宽,这也标志着语音通信已经真正转化为高品质音频通信的应用阶段。当然在基于互联网的音频通信中,声学回声和噪声一直是影响音频质量的最为关键因素之一。
声学回声消除成为提升音频通信质量的一个非常重要的环节。声学回声消除采用了自适应滤波来估计回声产生的回路特征,并不断修正自适应滤波器的系数,使得估计值更加逼近真实回声,最后从话筒信号中去除估计的回声,以达到回音消除的目的。
声学回声具有信号冲激响应时间长,特征分布范围广且多路径反射和时变的特点,自适应滤波器在估计回声路径的过程中容易受到这些不确定因素的干扰,当然外部环境的噪音也是一个重要的因素。
本系统结合多种已有信号处理算法,有效提升了声学回声的双工能力和收敛速度,并有效避免了使滤波器发散的多种因素,提升了滤波器的处理效率。同时利用高速浮点DSP 对回声消除和噪声消除进行了整体的实现。
系统采用了频域的MDF 自适应滤波算法,将MMSE No ise SupprESSo r 和多个VAD 添加到回声消除器中。在加入滤波器系数更新模块和非线性检测模块后,使得系统在更恶劣的噪音环境下以及双方通话过程中,一样具备良好的回声消除和噪音消除能力。整个核心运算部分均在频率域内完成,也大大降低了运算量,最后通过调整DSP 的数据结构,合理运用DSP 的资源和指令加速,实现了基于DSP 的高效能实时音频处理器的设计。
1 音频处理系统相关算法
1. 1 声学回声消除
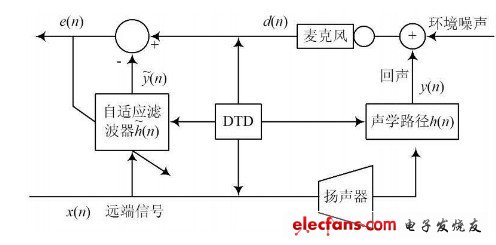
声学回声消除的基本原理是通过自适应滤波器估计声学回声路径的特征参数,产生一个模拟的声学路径,得出模拟的声学回声信号,并从参考信号中减去此信号,实现回声的消除。图1 给出了一个最为常见的声学回声消除器AEC 的原理图。
图1 声学回声消除器原理图
1. 2 结合噪音消除和静音检测的回声处理系统
1. 2. 1 MDF 滤波器基本结构和算法原理
MDF( Multidelay Block Frequency Domain Adaptive Filter) 是一种将原有的多阶滤波器分为K 个等分的子块,在每个长度为N 的子块能进行自适应滤波的方法。如此能降低多阶自适应滤波器大量的运算量。
F 表示对2N×2N 的矩阵进行FFT 变换,若v 表示信号帧序号,而diag 表示对角矩阵运算,则:
假设实际路径产生的回声信号为y ( v) ,通常也叫近端信号,则:
式中,^hk = [ ^hkN ,^hkN + 1 ,… ,^hkN + N- 1 ] T ,k = 0,1,2,,K - 1,它表示滤波器估计的第k 个子滤波器的系数。
1. 2. 2 改进的回声消除系统
如图2 所示,通过加入静音检测算法( VAD) 对输入信号的状态进行判断,不仅可以减轻实际的运算量,也可降低噪音对自适应滤波器的干扰,在一定程度上避免了滤波器发散的情况。同时加入MMSE Short t imeSpect ral Amplitude Estimator替代了传统的非线性处理器( NLP) 算法。在频域内对参与回声的频谱能量进行估计,计算增益,最后达到相对平滑的残余回声和噪音的处理。
图2 一种结合噪音消除的回声消除原理图
通过对滤波器状态参数的跟踪,根据滤波器当前是否正常收敛,残余回声估计模块的输出结果会自动调节估计值的大小,避免在滤波器正常收敛的情况下,抑制残余回声导致处理后正常信号损失过多的问题。
图2 中采用的静音检测算法( VAD) 采用了同时检测短时能量与过零率的方法,保证了判断的可靠性。
在远端语音不存在的时候,没有必要进行回声消除,只需要进行本地的噪音消除,若本地语音不存在则不需要做任何处理。
结合VAD 系统更有效地减少了对噪音和回音估计的误差范围,通过对滤波器系数更新的学习和调整功能使得在双方通话过程中音频信号具备更好的信噪比。
通过非线性信号检测模块加强了整体消除回音的能力。
2 基于DSP的音频处理系统实现
2. 1 硬件平台
DSP 的选型需要考虑运算速度、成本、硬件资源以及程序的可移植性等多个问题。由于算法的浮点特性,本文采用了美国德州仪器( T I) 的TMS320C6713B 浮点DSP 作为核心处理器,通过使用JT EG 标准测试接口、EDMA 控制器、GIPO 通用输入输出端口以及多通道音频缓冲串口( McASP) 等主要片外设备来完成系统的设计。
TMS320C6713B 可以工作在225 MHz 主频上,片内有8 个并行处理单元,分为相同的两组,其体系结构采用甚长指令字( V LIW) 结构,单指令字长为32 b,8 个指令组成一个指令包,总字长为256 b。L1 支持4 KB的程序缓存以及4 KB 的数据缓存,L2 支持64 KB 的缓存。32 b 的外部存储器接口( EMIF) 。与SDRAM 等无缝连接,可以寻址256 MB。
由于系统运行过程中需要实现的算法较多,仅依靠TMS320C6713B 的192 KB片内RAM 来执行程序是很困难的。本文使用了EMIF 的接口扩展了SDRAM 作为算法和数据的存储区域。采用TLV320AIC23B 实现音频输入和输出,AIC23 支持48 kHz 带宽、96 kHz 采样率的双声道立体声A/ D,D/ A,音频输入包括了*输入和线路输入。
系统的硬件平台如图3 所示。
2. 2 基于DSP 的软件实现
基于DSP 的实时处理的实现,本文将AIC23 采集到的数据先存储到SDRAM 中,在需要处理的时候利用EDMA 实现Ping Pong 缓冲,将待处理的数据分批搬运到片内存储器,结合高速缓存和片内内存设计合适的数据结构,并将数据对齐,这样大大减小了数据搬移带来的开销。
DSP 处理主流程图如图4 所示。
图4 DSP 处理主流程
基于Ping Po ng 缓冲结构的音频处理流程如图5所示。
图5 基于Ping Po ng 缓冲结构的音频处理流程
通过对音频处理算法中数据结构的调整和优化,将Ping Pong 缓冲架构的数据进行合理的安排,使得EDMA的数据传输和Process AEC 线程更好地并行处理。将当前需要处理的*信号和扬声器信号的数据保存在片内地址内,并将回声消除中用到的FFT 和扬声器参考数据均放在片内地址处理。将算法的其他辅助数据结构均放在SDRAM。这使得片内资源得到最大化利用,并且很大程度地提升了整个系统的运算效率。
参考TI DSP 相关优化资料,T I 的编译器选项使用-mv6700,-O3,-oiO,-pm 开关,使得编译的代码能更多地利用TMS320C6713B 的硬件资源和浮点指令,参考了TI 带的FFT 加速函数,结合实际算法做了局部的改进,使得所有算法最终在TI TMS320C6713B 上均能实时高效的运行。
3 结 论
声学回声消除以及噪音抑制等算法在多媒体通信的音频处理中起着至关重要的作用。
本文通过结合相关的自适应滤波器以及非线程处理和噪音抑制等算法,并在基于TI 的T MS320C6713B上实现和优化,实现了高效率的声学回声、噪声消除实时处理系统。通过实际应用表明,该系统对噪音消除可达40 dB以上,对回音消除可达50 dB 以上,并具备良好的双工处理能力。目前在本系统的基础上已经延伸扩展出了多路输入/ 输出的专业数字音频处理器,并实际应用在视频会议系统中,取得了较好的体验效果。
|
|


 发表于 2011-10-25 16:55:13
发表于 2011-10-25 16:55:13






 /1
/1 

